AI应用国产化迁移与服务器选型深度实战指南(2026版)

从NVIDIA 3090到国产昇腾、海光DCU,一线物联网开发者的真实选型历程。深度对比华为昇腾910B、海光DCU Z100等国产AI芯片与NVIDIA全系产品线,详解浪潮、新华三等服务器品牌适配矩阵。涵盖CUDA迁移三条路径、显存选型公式、网信办备案全流程及信创合规策略,附可直接落地的行动清单。适合正在纠结"国产还是英伟达"的AI应用开发者和企业技术决策者。
全文4.6万字,内容比较长,技术性内容不太理解的,可以直接看业务结论。
第一章:当AI遇见合规 — 一个物联网开发者的选型困局
1.1 一切始于一张3090
2025年下半年,我这启动了一个语音交互项目:用户通过语音与物联网系统对话,实现设备控制、数据查询等功能。
服务端技术栈:STT(语音转文字)+ LLM(大语言模型)+ TTS(文字转语音)+ 物联网平台,前者三个模块串联起来形成完整的语音交互闭环。测试环境里用一台英伟达RTX 3090显卡把整个流程跑通了——24GB的GDDR6X显存支撑了13B-q4量化参数的大模型,成熟的CUDA生态让PyTorch、vLLM这些框架大部分部署好就能用,开发过程虽然不是很快速,但是鉴于英伟达生态的成熟,遇到的问题比较少,即使有也很快就可以解决。
1.2 三个绕不开的现实问题
问题一:合规红线越来越近
根据《互联网信息服务深度合成管理规定》,利用生成式AI技术提供公共服务的企业,必须到网信办完成算法备案。我们的语音交互应用涉及STT识别、LLM生成、TTS合成,物联网funcation call调用,属于典型的深度合成服务。更关键的是,未来我们在智慧物联网领域会持续拓展AI能力——物联网智能体、AI辅助运维、智能告警分析……凡是涉及联网提供AI服务的,备案是迟早要走的路。
而备案的底层逻辑指向一个方向:国产化。虽然目前网信办尚未强制要求100%国产芯片,但在申报时展示"国产服务器+全栈国产软件栈"的架构,明显更容易通过审核。政策的风向已经很清楚了。
问题二:供应链焦虑挥之不去
RTX 3090毕竟是消费级显卡,性能有限,并不是为7×24小时企业级负载设计的。更大的隐忧在于:美国对华的芯片出口管制持续收紧,A100和H100已经被限制出口,即便是合规特供版(A800/H800),未来政策变动的风险始终悬在头顶。
问题三:性能天花板肉眼可见
3090的24GB显存跑7B模型流程跑通测试是足够了,但是用户体验上并不怎么样。当模型从7B升级到13B、甚至70B,当并发用户从1路增长到100路,单张3090就彻底扛不住了。70B模型即便做4-bit量化,也需要至少40GB显存;而3090的显存带宽(936GB/s)在多路并发推理时会成为明显瓶颈,语音对话反应迟钝,推理准确度不到80%。
1.3 这篇文章要解决什么
本文将覆盖以下核心内容:
市场全景:2026年国产AI服务器和芯片的真实格局(品牌、份额、参数、生态)
迁移方法论:从CUDA到国产芯片的完整迁移路径和工程实践
折中方案:国产服务器+英伟达芯片——当前项目最务实的落地路径
硬件选型公式:模型参数×精度 → 显存需求 → 芯片选型 → 服务器选型
合规全解读:网信办备案流程、信创要求、不同场景的合规策略
场景化指南:公网/封闭网络/政企/民企,不同场景下的最优选型路径
未来布局:从语音交互到物联网智能体,算力架构的演进方向
第二章:智算市场全景图 — 2026年国产服务器与芯片的"战国时代"
在动手选型之前,我们得先搞清楚一个基本问题:现在的国产算力市场长什么样? 这不再是三年前那个"只有昇腾能打"的时代了。
2.1 全球AI算力格局的剧变
从2023年到2026年,全球AI算力市场经历了一场深刻的结构性变化。
英伟达仍是王者,但城墙出现了裂缝。 2025年中国AI加速卡市场总出货量约400万张,其中英伟达占比约55%(约220万张),相比两年前超过80%的统治地位已经大幅下滑。与此同时,中国本土芯片厂商的市场份额攀升至约41%(约165万张),这个数字在2023年还不到15%。
推动这一变化的核心力量有三个:
出口管制:美国持续收紧对华AI芯片出口限制。A100/H100被禁后,英伟达推出了"中国特供版"(A800/H800),随后又推出性能进一步阉割的H20。但每一次合规调整,都在加速中国市场寻找替代方案的决心。
信创政策:国家对"信息技术应用创新"的推进力度空前。2025年被定为信创从党政领域向金融、电力、交通等"八大行业"深度渗透的关键年。
国产芯片自身的进步:华为昇腾910B已经能在大模型训练中对标A100;海光DCU的类CUDA生态让迁移成本大幅降低;寒武纪、摩尔线程等厂商也在推理市场站稳了脚跟。
一个值得记住的数据:2025年中国市场AI加速卡出货量中,华为昇腾以约81.2万张(占国产阵营近一半)位居国产芯片第一,其次是平头哥(约26.5万张)、昆仑芯和寒武纪(各约11.6万张)。
2.2 国产AI服务器品牌商:谁在承载算力?
AI服务器不是把一块GPU插到机箱里就完事了。散热设计、电源管理、卡间互联、固件兼容性、售后服务……这些决定了你的AI应用能不能在生产环境里稳定跑起来。
根据IDC 2025年上半年数据,中国AI服务器市场的格局如下:
浪潮、新华三、联想合计占据约50%的销售额份额;按出货量看,浪潮、新华三、宁畅合计约43%。
对于我这种物联网企业来说,有几个关键发现:
浪潮信息是"不会错"的选择——产品线覆盖英伟达和国产两条路线,同一个机箱可以灵活切换芯片方案,供应链和售后在国内几乎无人能出其右。
新华三的R5300 G6是"万金油"型号——4U空间里塞了10个双宽PCIe 5.0插槽,从英伟达到昇腾到海光到寒武纪,几乎所有主流加速卡都能安装。对于需要逐步从英伟达过渡到国产芯片的企业,这个扩展能力价值巨大。
华为Atlas走的是"苹果路线"——全栈自研,性能天花板最高,但生态相对封闭。如果你选了华为,基本就要All-in昇腾生态。
中科曙光是政务项目的"安全牌"——它在信创名录中的地位极高,搭配海光芯片(中科曙光与海光信息同属中科系),在信创合规评审中优势明显。
2.3 国产AI芯片四大阵营深度解读
现在我们把目光聚焦到最核心的部分——芯片。对于应用开发者来说,芯片决定了你的代码能不能跑、跑得快不快、改动量有多大。
2.3.1 华为昇腾(Ascend):全栈自研的"国产一哥"
架构:自研达芬奇(Da Vinci)3.0架构。这是一种专门为AI计算设计的异构架构,核心计算单元包括AI Cube(矩阵运算)、AI Vector(向量运算)和标量计算单元。
主力型号:
昇腾910B/910C:对标NVIDIA A100/H100的训练+推理旗舰。910B采用7nm工艺(中芯国际代工),FP16算力约320 TFLOPS,搭载64GB HBM3e显存,带宽1.2TB/s。这是目前国产芯片中唯一能够支撑大规模大模型训练的型号。DeepSeek-V3的部分训练就使用了昇腾910B集群。
昇腾310P:定位推理场景的"性价比之王"。功耗仅75-150W,INT8算力达140-280 TOPS。特别适合STT/TTS这种计算密度适中但对延迟敏感的任务,以及边缘AI部署。
软件栈:CANN(Compute Architecture for Neural Networks)是昇腾的计算架构。开发者通过torch_npu适配层使用PyTorch开发,将model.to('cuda')改为model.to('npu')。CANN 8.0+对PyTorch的原生支持度已超过90%。
生态评价:⭐⭐⭐⭐☆
优势:性能天花板最高,华为全栈支持(硬件+驱动+框架+工具链),社区活跃度国产最高
劣势:与CUDA生态差异较大,迁移需要一定投入;生态相对闭环,非昇腾框架支持较弱
2.3.2 海光DCU(深算系列):CUDA开发者的"最优迁移目标"
架构:基于GPGPU架构,兼容AMD ROCm技术栈。这一点非常关键——它意味着海光DCU的编程模型与NVIDIA CUDA高度相似。
主力型号:
软件栈:DTK(Deep-learning ToolKit),全面兼容ROCm。最核心的能力是:开发者可以用hipify工具自动将CUDA C++代码转换为HIP代码,大部分PyTorch/TensorFlow代码无需重写即可运行。
生态评价:⭐⭐⭐⭐☆
优势:迁移成本最低——对于原本在CUDA上开发的团队,海光可能是改动量最小的国产化选择
劣势:绝对算力和显存带宽不如昇腾910B上限,长期技术演进路线图相对保守
划重点:如果你的团队没有专业的AI基础架构能力(就像我们物联网公司一样),海光DCU的类CUDA生态可能是迁移阻力最小的选择。
2.3.3 寒武纪思元(MLU):推理场景的老牌玩家
架构:自研指令集和微架构,在云、边、端实现统一生态。
主力型号:
思元590/690:寒武纪最新一代推理芯片,INT8算力在256 TOPS以上。采用先进的芯粒(Chiplet)技术,对CNN和RNN(语音/视觉场景的核心网络架构)有针对性的硬件优化。
软件栈:Neuware SDK + MagicMind推理引擎。需要使用Neuware工具链进行算子转换。
生态评价:⭐⭐⭐☆☆
优势:推理优化深度大,在语音和视觉流式处理场景中性能突出;2025年已实现规模化盈利
劣势:自研指令集意味着迁移成本较高,生态开放度不及昇腾和海光
2.3.4 摩尔线程(Moore Threads):通用GPU的国产探索者
架构:自研MUSA架构,走通用GPU路线,强调"全功能"覆盖(AI计算+图形渲染+视频编解码)。
主力型号:
MTT S5000及下一代:近期在万卡智算集群解决方案(KUAE系列)方面发力,逐步从图形渲染向AI大模型训练与推理拓展。
生态评价:⭐⭐⭐☆☆
优势:通用GPU路线覆盖场景广,在AI+图形融合场景(如数字人、XR)有差异化优势
劣势:AI生态成熟度落后于昇腾和海光,大模型训练能力仍在追赶
2.4 核心参数硬对比
说再多文字不如一张表来得直接。以下是主流国产AI芯片与NVIDIA产品线的核心参数对比:
核心发现:昇腾910B在FP16算力和INT8算力上已经与A100处于同一量级,显存带宽(1.2TB/s)不及A100(2.0TB/s)
2.5 芯片与服务器品牌适配关系矩阵
选芯片和选服务器不是两个独立的决策——某些品牌服务器与特定芯片有"原生级适配",而其他组合可能需要额外的适配工作。
关键结论:如果你计划走"先英伟达,后国产"的两步走路线,新华三R5300 G6和浪潮NF5468M7是最优的服务器底座——它们同时深度支持英伟达和国产芯片,未来换卡不需要更换服务器机箱。
第三章:从CUDA到国产 — AI应用迁移的完整方法论
如果说第二章是在看菜单,这一章就是正式下厨了。作为一个没有专业AI底层能力的物联网团队,我最核心的关注点只有一个:迁移到底要改多少代码?会不会遇到改不动的底层拦路虎?
3.1 迁移前的问题
在开始任何迁移工作之前,你需要先回答这几个问题,答案直接决定了你应该选哪条路:
问题1:你的应用深度依赖CUDA的哪些特性?
把你的AI应用做一个"CUDA依赖度"分级:
大多数AI业务应用(包括我的语音交互系统)属于L1层级——我们用的是vLLM做LLM推理、FunASR做STT、CosyVoice做TTS,全部是基于PyTorch的高层框架调用。这意味着迁移的核心工作量集中在"环境适配",而非"代码重写",业务代码不需要重写,但是部署服务脚本需要适配修改。
问题2:你有多少专职的AI基础架构人力?
这个问题直接影响你选择哪条迁移路径。如果团队中没有人熟悉NPU编程、算子开发、异构计算调优——很正常,大多数应用型公司都是这样——那你需要选择迁移阻力最小的路径。
问题3:项目上线的时间压力有多大?
如果项目急着交付(比如我的情况),先用英伟达顶上,再逐步迁移国产是最理性的选择。如果时间充裕,一步到位上国产芯片可以省去二次迁移的成本。
3.2 三条迁移路径详解
基于上面的评估,我梳理出了三条从CUDA到国产化的路径。它们不是互斥的——实际上,最优策略通常是先走路径A快速上线,然后逐步切换到路径B或C。
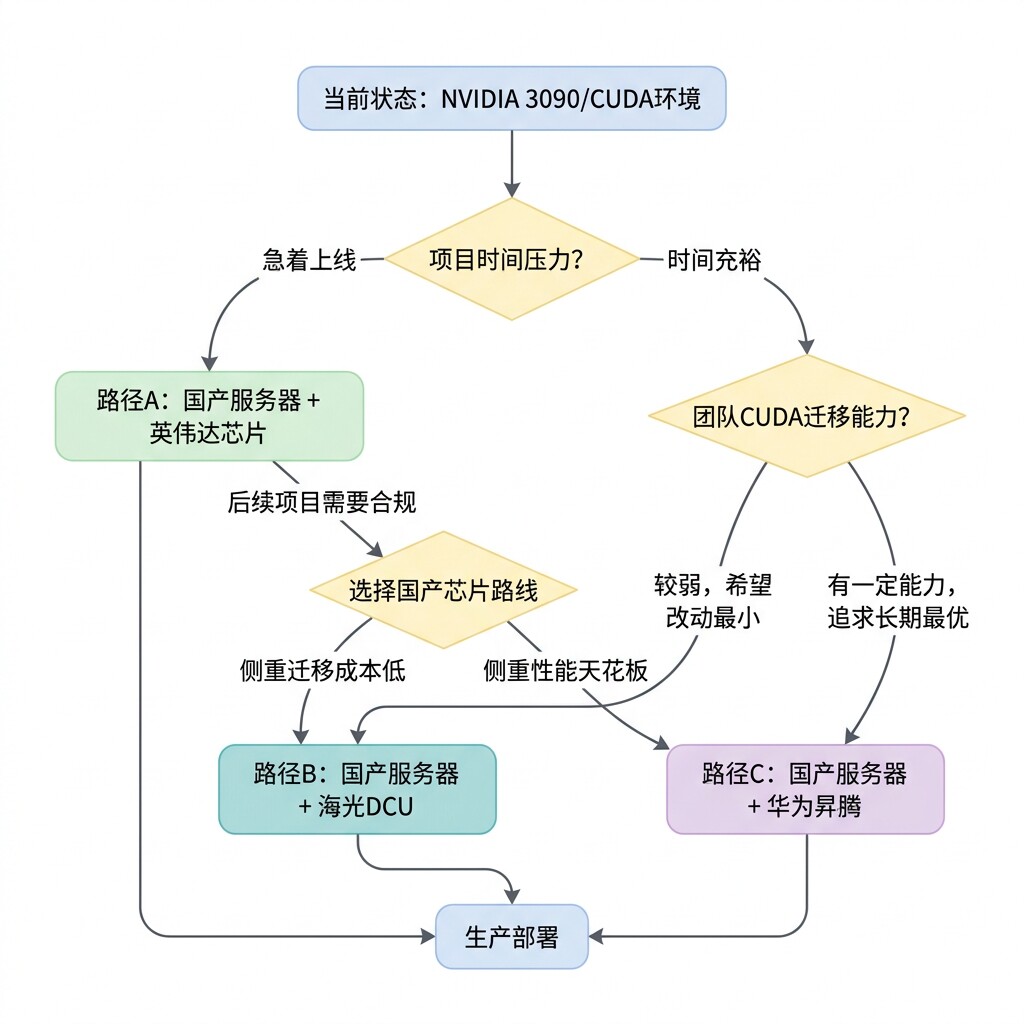
路径A:国产服务器 + 英伟达芯片(零迁移成本)
适用场景:项目急着上线 + 技术人力有限 + 暂时不需要网信办备案
核心逻辑:买浪潮或新华三的服务器,但芯片选英伟达的合规版本(如A800/L40S/H20)。你的代码、Docker镜像、部署流程完全不需要改动——从3090迁移到A800,就是把显卡换了一块,驱动更新一下。
迁移工作量:≈ 0(环境部署1-2天)
这条路径我会在第四章详细展开。
路径B:国产服务器 + 海光DCU(低迁移成本)
适用场景:需要国产芯片合规 + 团队以CUDA开发经验为主 + 不想大幅重构代码
核心逻辑:海光DCU兼容ROCm生态,开发者可以用hipify工具自动转换CUDA代码。对于PyTorch用户,安装支持DCU的特定分支后,大部分代码可以直接运行。
迁移工作量评估:
关键优势:hipify工具能自动完成大部分语法转换,把cudaMemcpy变成hipMemcpy,把cudaStreamSynchronize变成hipStreamSynchronize。对于我们这种主要使用框架层API的应用,迁移阻力极低。
路径C:国产服务器 + 华为昇腾(长期最优解)
适用场景:需要信创合规 + 追求性能天花板 + 有一定的技术投入意愿
核心逻辑:昇腾使用自研达芬奇架构,与CUDA差异较大。但好消息是:现在有两种方式降低迁移门槛。
方式一:框架层适配(推荐)
安装torch_npu库后,将代码中的device='cuda'改为device='npu'。对于标准的PyTorch模型,CANN 8.0+的算子覆盖率已超过90%,大部分代码可以直接运行。
# 原始 CUDA 代码
import torch
model = AutoModelForCausalLM.from_pretrained("model_path")
model = model.to('cuda')
# 昇腾 NPU 代码
import torch
import torch_npu # 新增一行
model = AutoModelForCausalLM.from_pretrained("model_path")
model = model.to('npu') # cuda → npu方式二:Runtime Shim(运行时垫片)
这是一个更"黑科技"的方案——使用类似ascend_compat的库,通过拦截CUDA API调用并动态重定向到NPU,实现代码一行不动就能在昇腾上运行。虽然性能可能不如原生适配,但对于快速验证可行性非常有价值。
迁移工作量评估:
3.3 迁移工程的关键步骤
无论选择路径B还是路径C,以下四个阶段是通用的:
阶段一:环境搭建(别小看这一步)
国产芯片最容易踩坑的地方就是环境配置。驱动版本、固件版本、CANN/DTK版本、PyTorch版本、Python版本——这些之间有严格的匹配关系,版本不对就是各种诡异报错。
最佳实践:
✅ 强烈建议使用厂商提供的官方Docker镜像。华为昇腾社区提供了CANN预装镜像,海光也有DTK官方镜像。这能省去50%以上的环境配置时间。
✅ 先用
npu-smi info(昇腾)或对应的设备检测命令确认硬件识别正常。❌ 不要直接在裸机上编译安装——国产环境对编译器版本(gcc/g++)、依赖库(protobuf等)有极其严格的兼容性要求。
阶段二:算子适配(核心战场)
这是迁移中工作量最大的部分。核心任务是确保你的模型在国产芯片上所有算子都能正确执行。
实操流程:
算子依赖分析:用PyTorch Profiler跑一遍模型推理,导出所有调用的算子列表,与目标平台(CANN/DTK)的算子库清单逐条比对。
基线建立:在NVIDIA环境下记录模型推理的完整输出(作为"黄金标准"),后续用来做精度对齐。
缺失算子处理:
优先check是否有等价的原生算子可以替代
其次尝试算子融合或组合替代
最后才考虑用TBE(昇腾)或HIP(海光)自定义开发
阶段三:精度校验(不能跳过)
不同硬件平台的浮点运算策略存在差异(FP16/BF16的舍入模式、指令调度顺序等),会导致计算结果产生微小误差。对于LLM来说,这些误差可能在层间累积,最终导致输出质量下降。
验证方法:逐层对比hidden_states输出,定位数值偏移的特定算子。通常精度偏差在0.1%以内可以接受。
阶段四:性能调优
开启图模式(Graph Mode):减少Python层的调度开销。昇腾的
ascend-turbo-graph和海光的图编译都能显著提升推理速度。卡间通信优化:使用平台优化的集合通信库(昇腾HCCL/海光MCCL),不要使用通用的OpenMPI。
显存管理:显式管理片上缓存,减少内存读写延迟。
3.4 实战踩坑经验
以下是从社区和实际迁移案例中总结的高频踩坑点:
坑1:device_map="auto" 的陷阱
在CUDA环境下,很多开发者习惯用device_map="auto"让框架自动分配模型层到不同GPU。但在国产芯片上,这个"auto"可能会把部分层错误路由到CPU,导致推理速度断崖式下降。建议显式绑定所有计算层到NPU/DCU设备。
坑2:自动转换工具不是万能的
hipify和类似工具只能解决60-80%的代码兼容性。剩余的20-40%通常涉及:
平台特有的内存管理API
CUDA特有的warp-level原语(如
__shfl_sync)与特定CUDA库(如Thrust)深度绑定的代码
坑3:通信库版本一定要匹配
如果你在做多卡推理(tensor parallelism),一定要使用平台优化的MPI版本和集合通信库。在昇腾上用通用的OpenMPI,卡间通信性能会比HCCL差3-5倍。
坑4:驱动和固件的"隐藏版本号"
国产芯片的驱动更新频率很高,而且不同版本之间可能存在不兼容。建议在项目初期就锁定一个经过验证的驱动+固件+CANN/DTK版本组合,不要轻易升级。
3.5 三条路径的成本对比总结
我的建议:对于像我这样的物联网应用型公司,最优策略是路径A起步 → 路径B或C逐步过渡。先用英伟达方案快速交付项目,同时安排1-2名工程师开始学习国产算力栈,为后续项目做技术储备。
第四章:先部署再进化 — 国产服务器+英伟达芯片的"折中路径"
这一章是我认为对于90%急着项目上线的团队来说最重要的内容。在大部分实际情况中,你面临的不是"要不要国产化",而是"什么时候国产化"。而在"现在"和"将来"之间,有一条非常务实的路径。
4.1 为什么这是最务实的第一步
让我说一句大实话:如果你的项目比较急要交付,国产芯片方案不是你现在应该纠结的事情。
迁移成本为零:从RTX 3090迁移到NVIDIA A800/L40S/H20,你的PyTorch代码、Docker镜像、部署脚本——基本上不用改(单卡变多卡仍需要开发)。换块卡,更新个驱动,齐活。
团队学习成本为零:你的工程师不需要学习CANN、DTK、torch_npu这些新概念。所有CUDA生态的工具链、调试工具、社区资源全部可以继续使用。
交付周期最短:从采购到部署上线,一到两周足够。对比国产芯片方案可能需要2-3个月的适配期,时间差距巨大。
硬件品质升级:从消费级的3090换成企业级的服务器形态,你得到的不仅是更好的算力——更重要的是企业级的散热设计、冗余电源、7×24小时运行稳定性,以及专业的售后服务。
一个关键认知:"国产服务器"≠"国产芯片"。你完全可以买一台浪潮或新华三的国产品牌服务器,里面装英伟达GPU。在很多非信创强制场景(民营企业、暂不联网的内部系统),这就够了。
4.2 英伟达芯片在中国的供货现状(2026年)
实话实说:
H20是目前最容易合规采购的选择,96GB HBM3大显存,虽然算力被阉割,但大显存意味着70B FP16可直接放下。
L40S更适合推理场景,48GB GDDR6显存在推理吞吐量和性价比上有优势。
存量A800/H800性能最强,但供货不稳定且价格高。
4.3 品牌服务器推荐(支持英伟达路线)
推荐一:浪潮 NF5468M7 — "双芯兼容"的常青树
支持8张双宽GPU(英伟达或国产芯片均可)
4×2000W钛金电源,满足7×24小时高负载运行
关键:同一机箱,后续可换成国产芯片——机箱、电源、散热全复用
推荐二:新华三 UniServer R5300 G6 — PCIe扩展之王
4U空间提供10个双宽PCIe 5.0插槽
已通过70+款AI加速卡兼容性认证
CloudOS平台实现异构算力统一调度
推荐三:超聚变 FusionServer G5500 V7 — 散热设计标杆
液冷/风冷混合散热设计
继承华为在服务器领域的技术积累和售后体系
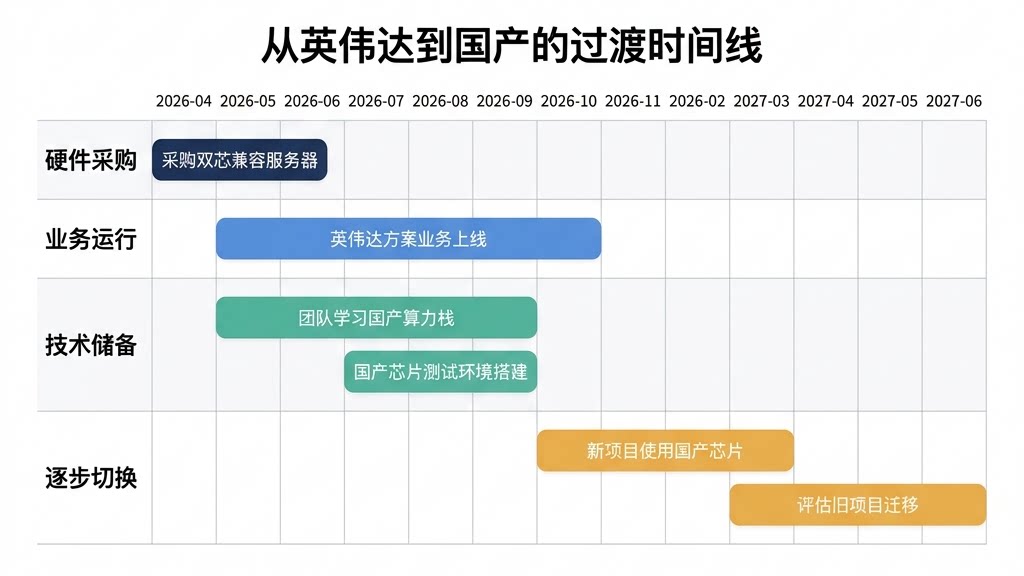
4.4 从英伟达到国产的平滑过渡策略
第一步:买"双芯兼容"的服务器底座(Day 0)
采购时选择同时支持英伟达和国产芯片的型号。确保机箱、电源、散热系统未来换卡时可复用。
第二步:英伟达方案快速上线(Month 1)
装上英伟达卡,直接部署现有CUDA环境镜像。业务上线,满足交付要求。
第三步:并行学习国产算力栈(Month 1-6)
安排1-2名工程师开始接触国产软件栈:
申请昇腾社区开发者账号,完成CANN基础教程
测试环境中用昇腾/海光小规模部署非核心模型
了解vLLM-Ascend插件使用流程
参加厂商技术培训或社区交流
第四步:新项目切换国产芯片(Month 6+)
团队积累经验后,新项目优先使用国产芯片方案。旧项目可继续在英伟达上运行或逐步切换。
4.5 落地操作清单
第一步:确认项目需求 — 评估模型参数大小和显存需求、确定并发用户数和延迟要求、明确是否有信创/备案硬性要求
第二步:服务器选型 — 与浪潮/新华三/超聚变沟通、确认"双芯兼容"能力、获取报价和交付周期
第三步:芯片选择 — 预算充足且需要大显存:H20(96GB);纯推理:L40S(48GB);有A800/H800渠道:优先采购
第四步:部署上线 — 直接部署现有Docker镜像、更新NVIDIA驱动、完整功能测试和压力测试
第五步:为未来做准备 — 预留PCIe插槽供国产卡测试、安排人员学习CANN/DTK、关注网信办备案最新动态
第五章:深入国产算力 — 模型参数×硬件配置的选型公式
选服务器不是"哪个贵买哪个",也不是"看别人用什么就跟着买"。科学的选型需要从你的模型参数出发,计算显存需求,再匹配到具体的芯片和服务器。
5.1 大模型参数与显存需求对应表
这是选型的核心公式。显存需求主要由三部分组成:模型权重 + KV Cache(上下文缓存) + 运行时开销。
经验公式:FP16精度下,模型显存占用 ≈ 参数量(B) × 2 GB。例如7B模型约需14GB,70B模型约需140GB。INT4量化后显存需求约为FP16的1/4。
重要提醒:以上仅为模型权重的显存占用。实际部署中需额外预留10-20%的显存用于KV Cache和计算缓冲区。长上下文场景(如32K tokens)的KV Cache开销会更大。
英伟达芯片的模型参数与显存选型对照表
注意:RTX A6000、A10、L4 目前均在美国对华出口管制清单内,正规渠道已无法直接采购。表中仍列出是为了提供性能参照基准。当前可合规采购的英伟达数据中心级产品主要是 H20 和 L40S。
对于我这的语音交互应用来说:
当前用7B模型,单张昇腾310P(24GB)就够了(1~5路并发,推理简单)
如果要升级到13B-34B,需要一张昇腾910B(64GB)(5~20路并发,推理相对复杂)
如果未来要跑70B级别的模型,至少需要2-4张910B
5.2 推理框架的国产化适配
在CUDA环境下,我们用vLLM做LLM推理已经非常成熟了。好消息是:vLLM官方已经推出了昇腾NPU的专用插件,这是目前国产芯片上大模型推理的标准路径。
vLLM-Ascend:昇腾推理的标准入口
vLLM社区采用"硬件插件"机制,将昇腾支持从核心代码中解耦。你不需要用魔改版vLLM,而是安装vllm-ascend插件即可。
支持的硬件:Atlas 800I A2/A3 推理系列、Atlas A2/A3 训练系列
环境要求:
Linux操作系统(推荐银河麒麟/统信UOS等信创OS)
Python 3.10
CANN 8.5.1+
torch + torch-npu(版本需匹配)
关键优化特性:
PagedAttention:显存高效管理,支持更多并发请求
Auto-prefix-caching:前缀缓存,降低长System Prompt的TTFT
Chunked-prefill:分块预填充,提升并发效率
量化支持:W4A16-AWQ 和 W8A8-SmoothQuant
图模式(Graph Mode):通过
ascend-turbo-graph消除Python调度开销
实操部署流程(简要版):
# 1. 确认NPU设备状态
npu-smi info
# 2. 创建Python虚拟环境
python -m venv vllm_env && source vllm_env/bin/activate
# 3. 安装vLLM和昇腾插件(版本号需匹配)
pip install vllm==x.y.z
pip install vllm-ascend==x.y.z
# 4. 启动推理服务(OpenAI兼容API)
python -m vllm.entrypoints.openai.api_server \
--model /path/to/model \
--tensor-parallel-size 2 \
--dtype float16海光DCU上的推理框架
海光DCU由于兼容ROCm,可以使用vLLM的ROCm分支或社区维护的DCU适配版本。另外,LLaMA-Factory等主流微调框架也已支持DCU环境。
5.3 STT/TTS模块的国产化适配
语音交互不仅仅是LLM推理。STT(语音识别)和TTS(语音合成)模块同样需要在国产芯片上运行。
STT模块(以FunASR/Whisper为例):
FunASR基于PyTorch开发,在昇腾上通过
torch_npu适配后可正常运行CANN 8.0+对标准PyTorch算子的覆盖率已超过90%
语音的FFT(快速傅里叶变换)等信号处理算子在国产芯片上已有原生支持
昇腾310P的音频/视频编解码硬件加速能力,可以直接在芯片内部完成语音流的解压与预处理
TTS模块(以CosyVoice/ChatTTS为例):
同样基于PyTorch,迁移路径与LLM类似
需要关注的算子:声码器(Vocoder)中的一些非标准卷积可能需要验证兼容性
如遇到缺失算子,优先使用CANN算子融合工具组合替代
5.4 性能基准测试数据
在语音交互场景中,用户感知到的延迟 = STT处理时间 + LLM首字延迟(TTFT) + Token生成时间 + TTS合成时间。其中LLM的TTFT和生成速率是影响体验的核心。
核心发现:对于7B级别的模型,昇腾910B的推理速度已经超过3090,TTFT也能控制在200ms以内——这在语音交互中是用户几乎无感的延迟。70B模型在910B上的表现也明显优于3090(3090需4-bit量化且速度慢)。
5.5 不同规模AI应用的硬件配置推荐
第六章:合规这道必答题 — 网信办备案与信创要求全解读
技术选型做得再好,如果合规不过关,项目照样上不了线。这一章我把合规相关的政策要求、备案流程、以及对硬件选型的影响掰开了讲。
6.1 谁需要备案?备什么?
根据《互联网信息服务深度合成管理规定》和《生成式人工智能服务管理暂行办法》,以下两类企业必须履行备案义务:
类型一:算法备案
适用对象:具有舆论属性或社会动员能力的深度合成服务提供者和技术支持者
覆盖范围:涉及算法推荐、深度合成(如TTS语音生成、LLM文本生成)的服务
备案系统:互联网信息服务算法备案系统
类型二:生成式AI服务备案
适用对象:面向公众提供生成式AI服务的企业
覆盖范围:利用生成式AI技术生成文本、图片、音频、视频的服务
对于我们的语音交互应用来说:STT识别结果生成、LLM对话回复、TTS语音合成——这三个环节都属于深度合成服务的范畴。如果未来要联网对外提供服务,备案是跑不掉的。
6.2 备案的完整操作流程
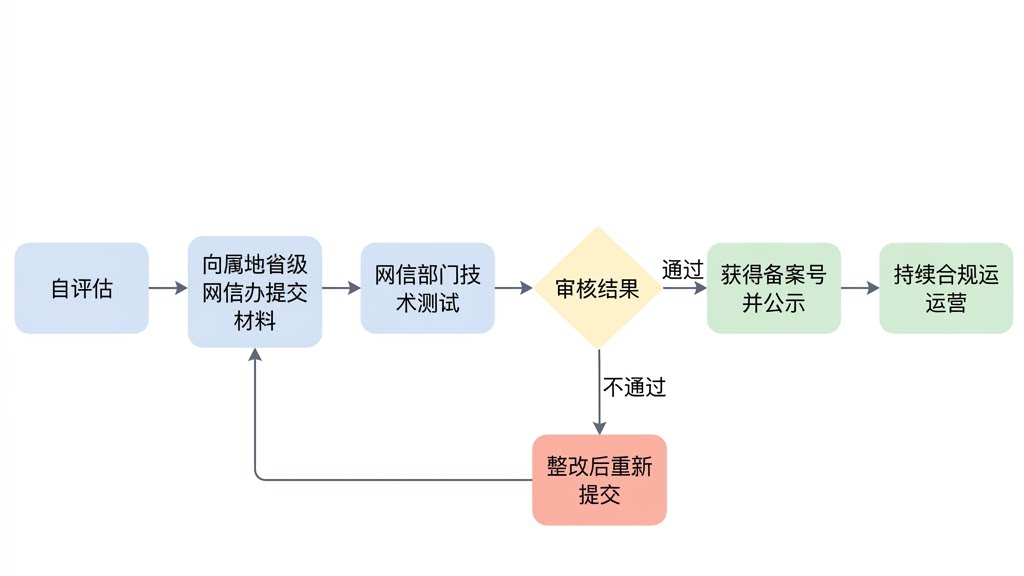
关键材料清单:
主体信息(企业资质、法人信息)
算法信息(模型基本原理、架构说明)
训练数据来源说明(版权合法、内容合规)
《算法安全自评估报告》
产品功能信息及安全措施说明
算力设施自主可控情况说明 ← 这一条越来越重要
地域趋势:截至2026年初,备案主体主要集中在北京(约25%)、广东和上海。在这些地区有深厚服务支持的服务器品牌商(如北京的中科曙光、广东的工业富联)在备案配合方面更有经验。
6.3 信创政策对硬件选型的影响
信创政策不只是"AI芯片要国产化"这么简单,它对整个技术栈都有要求:
关键时间节点:
2025年底前:党政及核心业务系统基本完成国产化替代
2026-2027年:金融、电力、交通等"八大行业"深度渗透
2028年+:预计信创要求将进一步扩展到更多民用领域
务实建议:如果你目前的项目不在信创强制范围内(如民营企业的内部系统),可以暂时使用英伟达方案。但如果项目涉及政务、金融、电力等行业客户,或者需要联网提供AI服务,尽早布局国产化是最安全的策略。
6.4 一个容易忽略的时间窗口
目前英伟达合规特供版(如H20)在中国仍然可以采购。但这个窗口在持续收窄:
这并不意味着你现在就必须All-in国产。但它意味着:你现在买服务器时,选一个能够兼容未来国产化切换的型号,是一个有远见的决策。
第七章:场景化选型指南 — 不同业务场景下的最优路径
不同的业务场景,对合规性、网络环境、性能要求各不相同。这一章我按场景拆解,给出具体的选型建议。
7.1 场景一:可通公网的民营企业AI应用
典型画像:物联网公司、SaaS企业、互联网创业公司,开发的AI应用需要联网运行但暂不涉及政务客户。
核心特点:
追求快速上线,时间就是金钱
成本敏感,不希望在基础设施上过度投入
合规压力适中——如果提供联网AI服务,未来需要备案
技术团队以应用开发为主,缺少AI基础架构能力
推荐路径:先用国产服务器+英伟达快速上线,并行启动国产化储备
推荐配置:
服务器:浪潮 NF5468M7 或 新华三 R5300 G6
芯片:NVIDIA L40S(推理为主)或 H20(需要大显存)
过渡计划:6个月内在测试环境验证昇腾/海光方案
案例:我自己这的语音交互项目就属于这个场景。当前急着交付,先用英伟达方案上线;后续项目如果要联网服务,再切换到国产芯片备案。
7.2 场景二:需要联网备案的AI服务
典型画像:面向公众提供AI对话、智能客服、AI写作等服务的企业。
核心特点:
必须满足网信办备案要求
长期合规是刚需,不能有侥幸心理
需要展示算力自主可控能力
推荐路径:直接上国产服务器+国产芯片
推荐配置:
芯片选择:昇腾910B(性能优先)或 海光DCU(迁移成本优先)
服务器:与芯片厂商深度适配的品牌(昇腾选华为/超聚变,海光选中科曙光)
软件栈:全信创——银河麒麟OS + CANN/DTK + vLLM-Ascend
7.3 场景三:完全封闭网络的政务/国企部署
典型画像:政府单位、军工企业、金融核心系统,物理隔离网络环境。
核心特点:
信创是硬性要求,从CPU到OS全部国产化
数据不出域,所有计算在私有环境完成
无法访问互联网下载依赖,所有软件包需离线安装
安全审计要求极高(三员管理等)
推荐路径:全信创架构 + 信创AI一体机
推荐配置:
CPU:鲲鹏(ARM)或 海光(x86)
AI芯片:昇腾910B/310P
操作系统:银河麒麟 V10 / 统信 UOS
部署方式:建议采用信创AI一体机——将服务器、芯片、OS、AI框架和预训练模型打包为一体的交付方案,实现开箱即用
容器化:使用信创版Kubernetes进行AI环境的快速交付与资源调度
特殊注意:
所有训练、微调、推理均在私有算力池完成,禁止远程API调用或自动更新
大模型选择开源模型(如Qwen、DeepSeek)进行私有化微调
需要提前打包所有Python依赖和模型权重,制作离线安装包
7.4 场景四:物联网智能体与边缘AI
典型画像:我这种物联网公司未来的方向——在设备端和边缘端部署轻量化AI。
核心特点:
云边端协同,不是所有计算都在云端完成
边缘设备功耗和体积受限
低延迟要求(设备控制需实时响应)
多设备管理和数据聚合
推荐架构:
云端:昇腾910B集群(承载大模型推理和模型更新)
边缘:昇腾310P / Atlas 500 边缘智能服务器(承载轻量推理和实时感知)
端侧:昇腾310等低功耗NPU(嵌入式设备上的极简推理)
7.5 综合决策矩阵
第八章:面向未来 — 物联网智能体时代的算力布局
走到这里,选型的问题基本已经解决了。但我们不能只看脚下的路,还要抬头看方向。作为一个物联网开发者,我更关心的是:未来3-5年,我们的算力需求会怎么变化?现在的选型决策能不能支撑未来的业务演进?
8.1 从语音交互到物联网智能体
我当前的语音交互应用只是AI与物联网结合的第一步。按照我的产品规划,后续会逐步演进为:
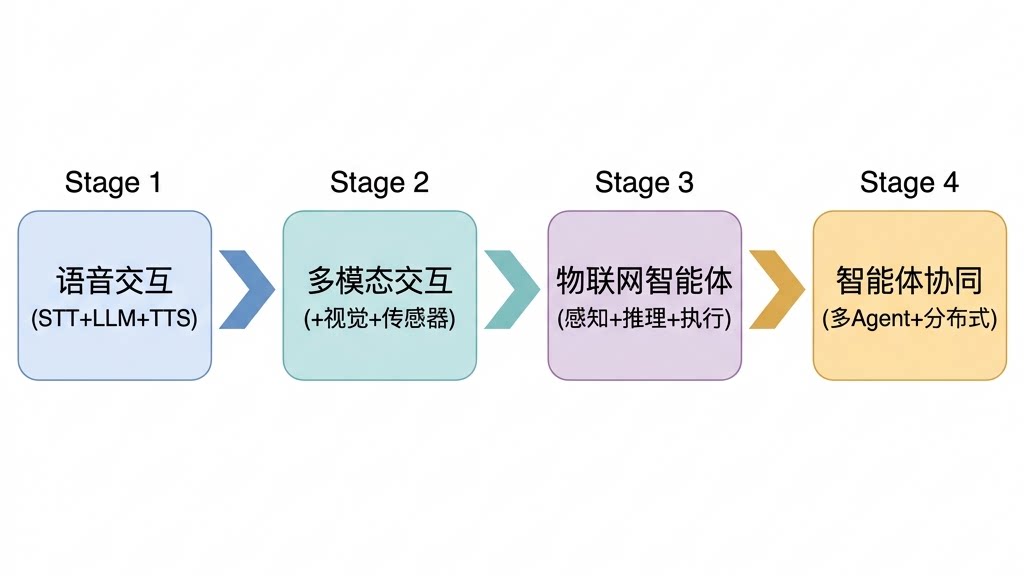
语音交互(现在) → 用户通过语音与IoT系统对话,实现设备控制和数据查询 多模态交互(1-2年) → 增加视觉能力(摄像头分析)、传感器数据理解,实现更丰富的人机交互 物联网智能体(2-3年) → AI不仅能理解指令,还能自主感知环境、推理决策、调用IoT API执行操作 智能体协同(3-5年) → 多个AI Agent协同工作,分别负责能耗管理、设备运维、安全巡检等
8.2 智能体对算力的新需求
从语音交互进化到物联网智能体,算力需求会发生质变:
这意味着:如果你现在选型时只考虑跑7B模型,那服务器很快就会成为瓶颈。建议在硬件选型时至少预留2倍的算力余量:
当前需要1张昇腾310P → 建议选能装4张卡的机型
当前需要1张910B → 建议选8卡位的服务器,先装2张,后续扩展
8.3 国产芯片的发展路线图
国产芯片的迭代速度正在加快。根据各厂商公开的技术路线图和行业预测:
华为昇腾950系列(预计2026-2027年):将采用更先进的制程工艺,算力和显存带宽进一步提升,有望在大模型训练场景中对标NVIDIA H100/H200
海光下一代DCU:持续增强与ROCm生态的兼容性,并在"内生安全"特性上做深度强化
寒武纪新一代思元:在边缘推理和视觉场景持续强化,算子库覆盖率提升
生态层面:算子开发正从"专家手写"向"AI自动生成"演进,迁移门槛会持续降低
一个乐观的判断:到2028年,国产芯片的软件生态成熟度有望达到CUDA的80-90%。届时"迁移难"将不再是选择国产芯片的主要阻力——价格和供货稳定性反而会成为国产芯片的核心竞争力。
8.4 给物联网企业的技术储备建议
现在就开始培养团队的国产算力能力。不需要投入太多人力——1-2个人兼职学习即可。参加昇腾社区的在线课程、关注海光的技术blog、在测试环境中跑几个demo模型。
关注FlagOS等跨平台框架。智源研究院推出的"众智FlagOS"旨在屏蔽不同国产芯片间的底层差异,实现"一次开发,多芯通用"。这类抽象层的成熟会极大降低迁移成本。
参与国产算力生态建设。加入华为"光合组织"或昇腾社区,不仅能获得技术支持,还能影响未来算子库的开发优先级。
选硬件时留够扩展空间。宁可多买一个大一号的服务器机箱,也不要为了省几万块钱买一个插槽不够的。
第九章:总结与行动清单 — 选型参考
9.1 全文核心观点回顾
经过七个章节的深入分析,让我把核心结论浓缩为三句话:
国产芯片已经"能用"了——昇腾910B对标A100、海光DCU兼容CUDA,国产芯片在技术上已经不是"能不能跑"的问题,而是"迁移要花多少精力"的问题。
"先英伟达,后国产"是最务实的路径——对于大多数应用型企业来说,先用国产服务器+英伟达芯片快速交付项目,然后在后续项目中逐步切换到国产芯片,是风险最低、成本最优的策略。
服务器选型时要"双芯兼容"——买能同时支持英伟达和国产芯片的服务器底座(如浪潮NF5468M7或新华三R5300 G6),未来换芯片不需要换服务器,这是一笔长期投资。
9.2 最终选型参考
回到最初的问题——我的语音交互项目应该买什么服务器?
当前项目(急着上线):
✅ 服务器:浪潮 NF5468M7
✅ 芯片:NVIDIA L40S × 2(48GB显存,推理性能足够,合规可采购)
✅ 部署:直接迁移3090环境的Docker镜像
📅 上线时间:采购后2周内
下一个需要联网备案的项目:
✅ 服务器:同一台浪潮NF5468M7(换卡即可)
✅ 芯片:华为昇腾910B × 2(64GB HBM3e,性能天花板高)
✅ 软件栈:CANN 8.5+ / torch_npu / vLLM-Ascend
📅 迁移周期:预计6-8周
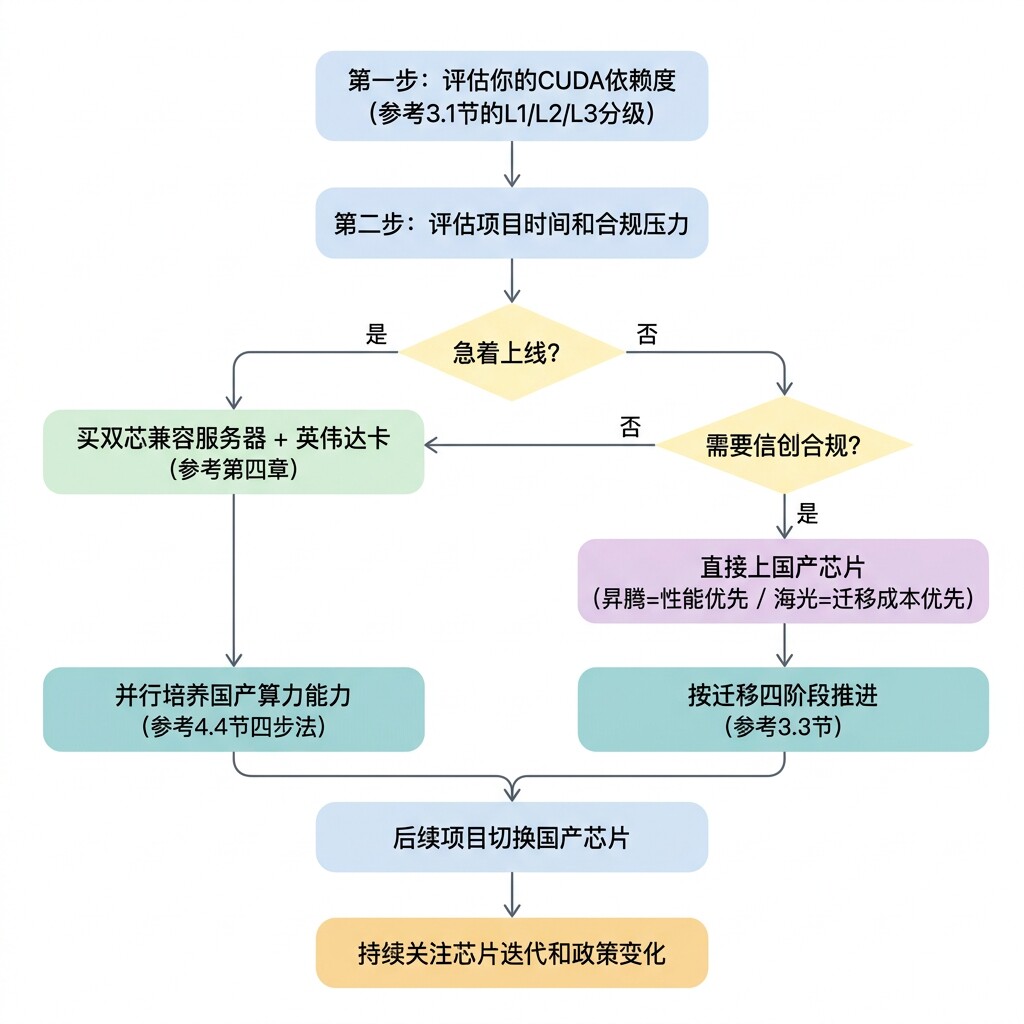
9.3 行动清单
---
本文内容基于2026年4月最新智算市场调研,数据引用自IDC行业报告、网信办公开文件、各硬件厂商官方技术文档及开源社区资料。芯片具体参数可能因型号版本不同而有差异,建议以厂商最新手册为准。